The quick-sort algorithm has been developed by Tony Hoare in 1960, with expected O(n log n) comparisons and O(log n) memory space to sort n items. The quick-sort outperforms others algorithms in practice, but it has no guarantee: when it spins off the road the complexity becomes quadratic. Like every classic recipe, quick-sort has many variants. Indeed writing a robust implementation that avoids quadratic response time reveals challenging, but that’s another story. Here is a naive quick-sort implementation:
/**
* @param lo index of the first sorted element
* @param hi index of the last sorted element
*/
static void quickSort(int[] array, int lo, int hi) {
if (hi <= lo) return;
int pivot = array[hi], firstBig = lo, tmp;
for (int i = lo; i < hi; i++) {
if ((tmp = array[i]) < pivot) {
array[i] = array[firstBig];
array[firstBig++] = tmp;
}
}
array[hi] = array[firstBig];
array[firstBig] = pivot;
sort(array, lo, firstBig - 1);
sort(array, firstBig + 1, hi);
}The insertion sort is a quadratic sorting algorithms. Despite of its poor asymptotic performance, the insertion sort reveals to have a lot of interesting properties.
- It is a simple iterative algorithm. Theses few lines of code outperform others algorithms on small datasets.
- It is efficient on almost sorted arrays.
/**
* @param lo index of the first sorted element
* @param hi index of the last sorted element
*/
static void insertionSort(int[] array, int lo, int hi) {
for (int i = lo + 1; i <= hi; i++) {
int val = array[i], j;
for (j = i; j > lo && array[j - 1] > val; j--) {
array[j] = array[j - 1];
}
array[j] = val;
}
}Insertion sort is faster on arrays smaller that 300 elements.
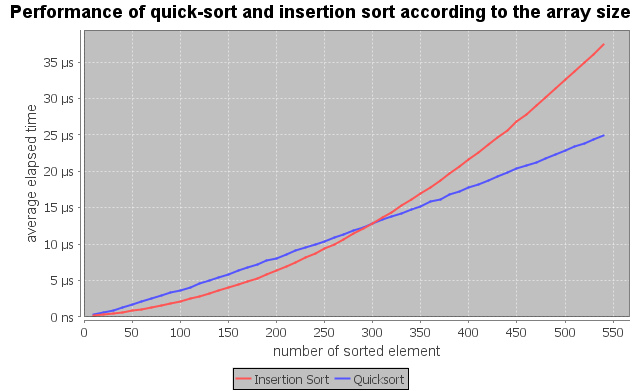
The quick-sort spends a lot a time sorting small arrays, and it would be faster to use insertion sort to finish the work. We can reap the best of the both, using quick-sort for the rough-in phase, and switch to the insertion when the arrays is small.
Bob Sedgewick developed an implementation of this idea. When quick-sort is called on a small arrays, we do nothing. When the quick-sort returns the array is almost sorted and a single insertion sort pass on the whole array finishes the job. We implement it by replacing the quick-sort end condition by:
if( hi - lo < cutoff ) return;The best value for cutoff can be found experimentally. The following chart shows the elapsed time required to sort one million integer according to the cutoff value.
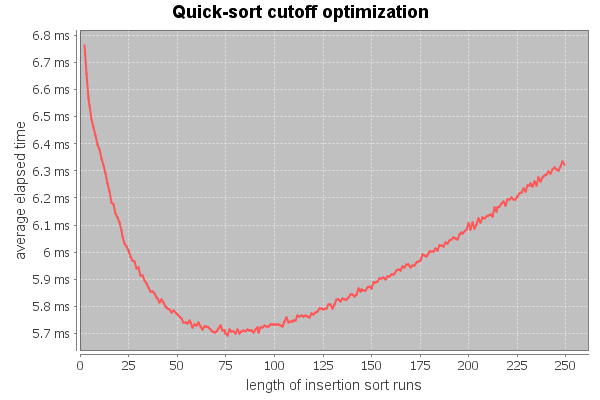
The best value is around 75 for theses two implementations. It may vary according to the relative efficiency of quick-sort and insertion sort implementations.
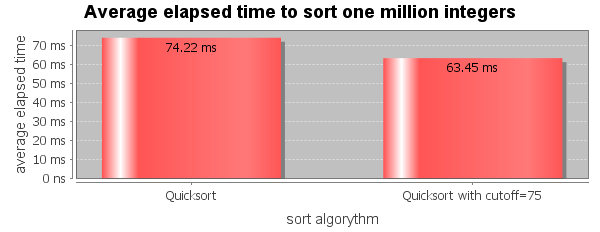
Switching from quick-sort to insertion sort for small array increase the overall speed by 14% which is significant. The optimal cutoff can be found experimentally and is around 75.
Footnotes on sorting performances:
- It is possible to get rid of boundary check of insertion sort by using a sentinel value.
- The median of three random element is a a robust quick-sort pivot selection method.
- Three-way partitioning avoids quadratic time induces by repeated values.
- Least significant radix sort combined with counting sort outperforms quick-sort for integers.
Footnote regarding experimental data:
- Measures are performed on a Java Hotspot, started in server mode.
- The elapsed time is the average of 400 samples measured after the warm-up phase.
- The benchmark harness and implementations is available at https://github.com/piwicode/algorithms.